
知识图谱落地应用
· 2020-04-03 14:34:07 · 北京瑞铭安普科技有限公司 知识图谱本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。知识图谱是关系的最有效的表示方式。通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。

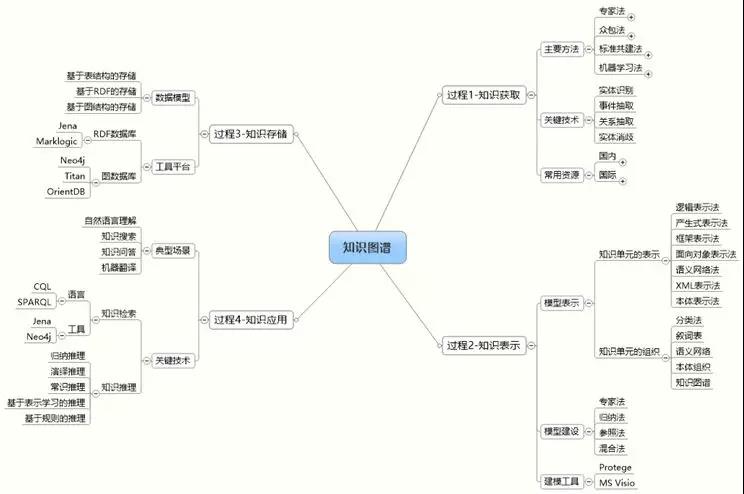
整个过程分成六个方面:
我们既可以通过网络爬虫爬取,也可以通过事件抽取(如使用 CRF 和 LSTM 等机器学习算法),还可以通过国内与国外的一些开源数据集来实现。
在获取到了知识之后,我们要对知识进行加工表示。我们既可以用到逻辑表示、框架表示、语义表示,也可以用到各种词表、本体组织,还可以用到语义网络、以及文本与语义的分类方法。
在完成模型表示之后,我们需要进行各种模型的建设。当前,国内业界普遍采用的方法是专家法和归纳法,当然,参照法也有被用到。
所谓专家法,就是根据团队自身对于现有业务和行业的理解程度,通过人工来建模表示。
而归纳法,则是通过一些归纳算法、人工归纳、以及文本分类的方法,来进行模型的归纳。
我们混合使用了上述两种方法。而在建模工具方面,当属 Protege 和 MSVisio 最为常用。
接着要进行的是知识存储,如前所述,我们需要选择一款数据库,包括:MySQL、SQL Server、MongoDB、Neo4j 等,不一而足。
根据我们过往的屡次实验经验,您可以先将数据存放到 Key-Vaule 类型的数据库中,而在后续需要的时候,再往 Neo4j 之类的图数据库中拉。
这种模式的性能要比直接存储要高一些。而在工具平台方面,Neo4j、Titan、以及 Cayley 都十分常用。
确定了存储方式,后面就是知识应用。它包括自然语言理解、知识搜索、知识问答、以及机器翻译等典型的应用场景。
业界一般在模式上分为两种:
在知识应用中,常用的关键技术包括:CQL、SPARQL、Jena、Neo4j、以及归纳、演绎和基于规则学习的推理。
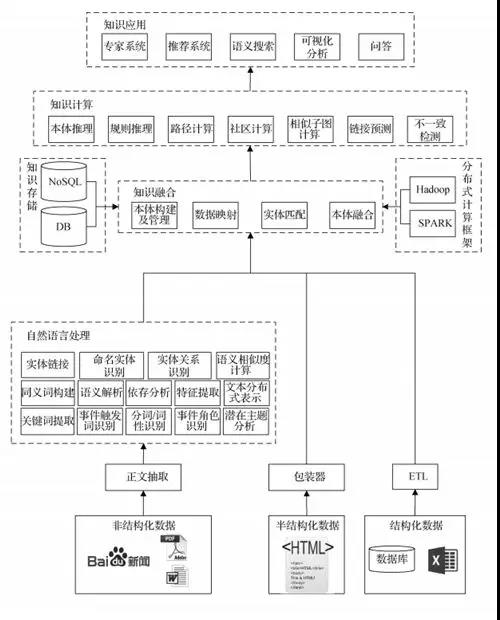
上图是一张非常经典的知识图谱整体架构图,让我们一起从下往上来解读这张图:
知识图谱落地
 建立一套知识的模型
建立一套知识的模型
如何获取知识
如何做好知识的融合如何实现知识的存储
如何保证知识的计算
高效地开展知识应用知识获取
知识表示
知识存储
知识应用
-
检索模式。在已经建立好的现成知识库图谱的基础上,我们将需要理解或翻译的句子,放到库里进行“答案”检索,再通过语义分析来进行匹配。最终将匹配出来的结果反馈给用户。可见,这是一种理解自然语言的常用场景。
-
混合模式。在检索模式的基础上,我们添加了深度自我生成的模型,以应对在知识库或语义库的匹配效果不佳的情况下,利用 RNN(循环神经网络)和 LSTM(长短期记忆网络)来生成智能模型。
-
通过百度搜索、Word 文件、PDF 文档或是其他类型的文献,抽取出非结构化的数据。
-
通过自然语言处理技术,使用命令实体识别的方式,来识别出文章中的实体,包括:地名、人名、以及机构名称等。
-
通过语义相似度的计算,确定两个实体或两段话之间的相似程度。
-
通过同义词构建、语义解析、依存分析等方式,来找到实体之间的特征关系。
-
通过诸如 TF-IDF 和向量来提取文本特征,通过触发事件、分词词性等予以表示。
-
通过 RDA(冗余分析)来进行主题的含义分析。
-
使用数据库或数据表进行数据存储。
-
针对所提取出来的文本、语义、内容等特征,通过知识本体的构建,实现实体之间的匹配,进而将它们存放到 Key-Value 类型的数据库中,以完成数据的映射和本体的融合。
-
当数据的体量过大时,使用 Hadoop 和 Spark 之类的分布式数据存储框架,再通过 NoSQL 的内容将数据存过去。
-
当需要进行数据推理或知识图谱的建立时,再从数据中抽取出各类关系,通过各种集成规则来形成不同的应用。






- 2018-11-20
- 下一篇:知识图谱落地应用场景