
知识图谱落地应用场景
· 2020-04-03 14:44:08 · 北京瑞铭安普科技有限公司知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。

我们先来看看知识图谱的发展历史:
-
50 年代到 70 年代,符号逻辑、神经网络、LISP(List Processing语言)、还有一些语义网络已经出现,不过尚处于简单且不太规范的知识表示形式。
-
70 年代到 90 年代,出现了一些专家系统,一些限定领域的知识库(如金融、农业、林业等领域),以及后来出现的一些脚本、框架、推理。
-
90 年代到 00 年,出现了万维网、人工大规模知识库、本体概念、以及智能主体与机器人。
-
00 年到 06 年,出现了语义 Web、群体智能、维基百科、百度百科、以及工作百科之类的内容。
-
06 年至今,我们对数据进行了结构化。但是数据和知识的体量越来越大,因此导致了通用知识库越来越多。随着大规模的知识需要被获取、整理、以及融合,知识图谱应运而生。
-
2010 年,微软发布了 Satori 和 Probase,它们是比较早期的数据库,当时图谱规模约为 500 亿,主要被应用于微软的广告和搜索等业务。
-
接着在 2012 年,谷歌推出了 Knowledge Graph(知识型图数据库),当时的数据规模有 700 亿。
-
后来,Facebook、阿里巴巴、以及亚马逊也相继于 2013 年、2015 年和 2016 年推出了各自的知识图谱和知识库。它们主要被用在知识理解、智能问答、以及推理和搜索等业务上。
我们预计至 2020 年,文本的数量有望突破 1 亿万件(某一特定类别)。那么,我们现在所面临的问题包括:数据量的庞大、非结构化的保存、以及历史数据的积累等方面。
知识图谱常见应用场景
-
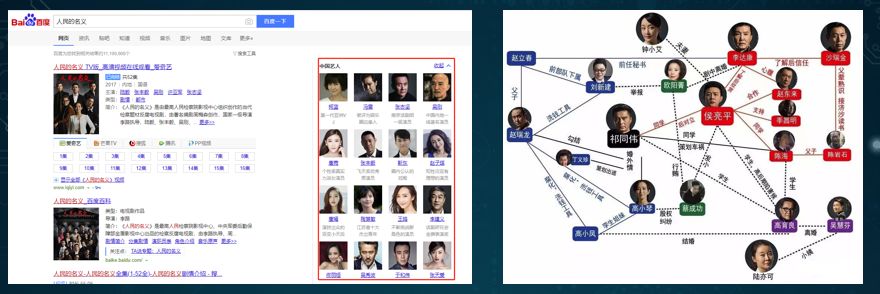
智能语义的搜索。例如:我们通过搜索引擎把各种知识点、实体、以及内容结合起来,形成实体之间的关系。
-
个性化的推荐。例如:我们在网购和浏览头条新闻时,下一次打开某个 App 所看到的内容,往往是该系统根据上一次搜索过的相关内容所做出的个性化推荐。
-
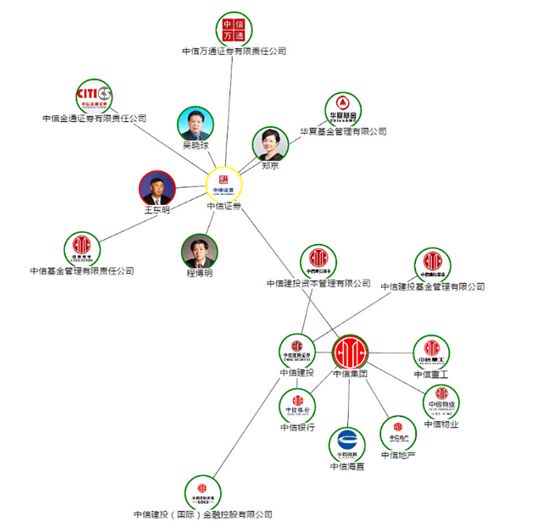
智能问答。比如:某家空调公司需要上线一个“知识问答”功能。那么他们既要收集本领域的电器相关知识,又要从外部实体那里抽取电路设计、功率设计、能耗设计、智能程度和用电量等方面的知识。
因此,他们会通过推荐或者是知识的抽取与融合,将结果保存到分布式图数据库里,进而发现各个点与点之间或是边与边之间的关系。
-
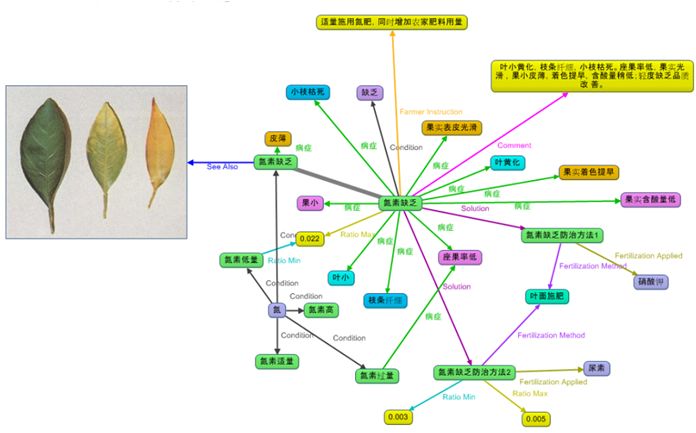
通过对数据的搜寻,发现在同一个数据库中不同节点所包含的共同字段和属性。
-
通过知识的融合与发掘、以及文档内容的语义,提取文字或标题的中心内容,再运用算法分析,采用主体之间的对比方式,找到两个用户之间可能存在的关系,进而建立一个知识体。







- 2018-11-15
- 下一篇:智慧社区应该怎样建设,有哪些注意事项